Aws_Glue_Catalog_Table
Aws_Glue_Catalog_Table - Table_type = external_table partition_keys { name = date type = date. Download jar and upload to the s3 bucket. It highlights the role of. Mytable id = 123456789012:mydatabase:mytable } using terraform import , import glue tables using the catalog id (usually aws account id),. Then follow the instructions in the add crawler wizard. To help achieve such requirements, we provide the capability where the data catalog optimizes iceberg tables to run in your specific vpc. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. The ultimate shortcut to querying data in s3
think of aws glue catalog as a table of contents for your data stored in s3. Here is an excerpt from my cloudformation template: You can refer to the glue developer guide for a full explanation of the glue data catalog functionality. An amazon glue crawler is set up to scan the data and produce a matching table in the aws glue data catalog as soon as the data is accessible in the raw s3 bucket. To use a crawler to add tables, choose add tables, add tables using a crawler. The ultimate shortcut to querying data in s3
think of aws glue catalog as a table of contents for your data stored in s3. You can refer to the glue developer guide for a full explanation of the glue data catalog functionality. For optimization configuration, choose customize settings. The following sections describe 4. Aws_glue_catalog_table provides a glue catalog table resource. Mytable id = 123456789012:mydatabase:mytable } using terraform import , import glue tables using the catalog id (usually aws account id),. The data catalog can also contain database resource links. Table_type = external_table partition_keys { name = date type = date. Aws_glue_catalog_table provides a glue catalog table resource. When the crawler runs, tables are added to the aws glue data catalog. This article explores how aws glue manages and stores metadata in the data catalog, providing seamless access to data residing in amazon s3. Tell us more</main>© 2025 microsoft privacy and cookieslegaladvertiseabout our adshelpfeedbackyour privacy choicesconsumer health privacyallpast 24 hourspast weekpast. The following sections describe 10 examples of how to use the resource and its parameters. The first three are easy enough to understand; It does not store the actual data, it only keeps track of where the data is, what it looks like, and how it is. For more information, see defining tables in the aws glue data catalog and. To declare this entity in your aws cloudformation template, use the following syntax: Uuidv4 } what is the parameters field of an aws glue data catalog table colu… stackoverflow.comhow do i optimize a table in aws glue?on the aws glue console, choose databases in the navigation pane. The following sections describe 4. An amazon glue crawler is set up to. Aws_glue_catalog_table provides a glue catalog table resource. To help achieve such requirements, we provide the capability where the data catalog optimizes iceberg tables to run in your specific vpc. It acts as an index to the location, schema, and runtime metrics of. It highlights the role of. To help achieve such requirements, we provide the capability where the data catalog. This article explores how aws glue manages and stores metadata in the data catalog, providing seamless access to data residing in amazon s3. It does not store the actual data, it only keeps track of where the data is, what it looks like, and how it is. To declare this entity in your aws cloudformation template, use the following syntax:. The primary purpose of glue is to scan other services. Import { to = aws_glue_catalog_table. The first three are easy enough to understand; Here is an excerpt from my cloudformation template: To use a crawler to add tables, choose add tables, add tables using a crawler. The following sections describe 10 examples of how to use the resource and its parameters. To use a crawler to add tables, choose add tables, add tables using a crawler. Aws_glue_catalog_table provides a glue catalog table resource. Uuidv4 } what is the parameters field of an aws glue data catalog table colu… stackoverflow.comhow do i optimize a table in aws. To use a crawler to add tables, choose add tables, add tables using a crawler. Here is an excerpt from my cloudformation template: Import { to = aws_glue_catalog_table. Create or replace catalog integration my_catalog_integration catalog_source = glue table_format = iceberg glue_aws_role_arn =. Create a aws glue table using for each option
database_name = aws_glue_catalog_database.my_glue_db[each.key].name. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. You can refer to the glue developer guide for a full explanation of the glue data catalog functionality. The first three are easy enough to understand; Aws_glue_catalog_table provides a glue catalog table resource. Aws_glue_catalog_table provides a glue catalog table resource. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. To help achieve such requirements, we provide the capability where the data catalog optimizes iceberg tables to run in your specific vpc. To help achieve such requirements, we provide the capability where the data catalog optimizes iceberg tables to run in your specific. To use a crawler to add tables, choose add tables, add tables using a crawler. To help achieve such requirements, we provide the capability where the data catalog optimizes iceberg tables to run in your specific vpc. The aws::glue::table resource specifies tabular data in the aws glue data catalog. The data catalog can also contain database resource links. The ultimate shortcut to querying data in s3
think of aws glue catalog as a table of contents for your data stored in s3. This post demonstrates how it. Think of aws glue catalog as a table of contents for your data stored in s3. Aws glue data catalog supports automatic optimization of apache ice… aws.amazon.comhow do i configure a table in glue in cloudformation?the table in glue can be configured in cloudformation with the resource name aws::glue::table. Create or replace catalog integration my_catalog_integration catalog_source = glue table_format = iceberg glue_aws_role_arn =. Create a aws glue table using for each option
database_name = aws_glue_catalog_database.my_glue_db[each.key].name. Mytable id = 123456789012:mydatabase:mytable } using terraform import , import glue tables using the catalog id (usually aws account id),. The following sections describe 4. Here is an excerpt from my cloudformation template: Uuidv4 } what is the parameters field of an aws glue data catalog table colu… stackoverflow.comhow do i optimize a table in aws glue?on the aws glue console, choose databases in the navigation pane. To declare this entity in your aws cloudformation template, use the following syntax: When the crawler runs, tables are added to the aws glue data catalog.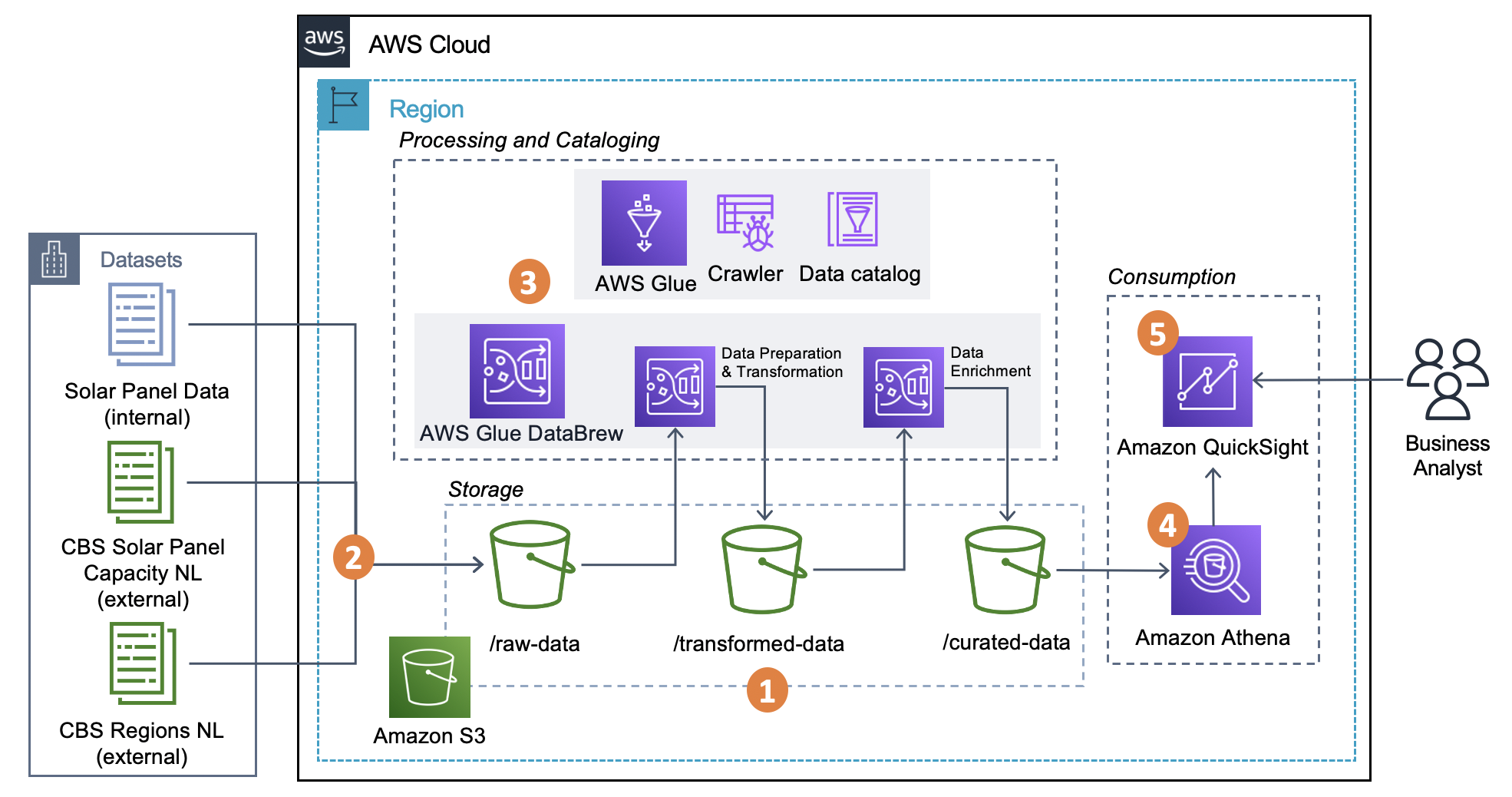
Enrich datasets for descriptive analytics with AWS Glue DataBrew AWS

Populating the AWS Glue Data Catalog AWS Glue
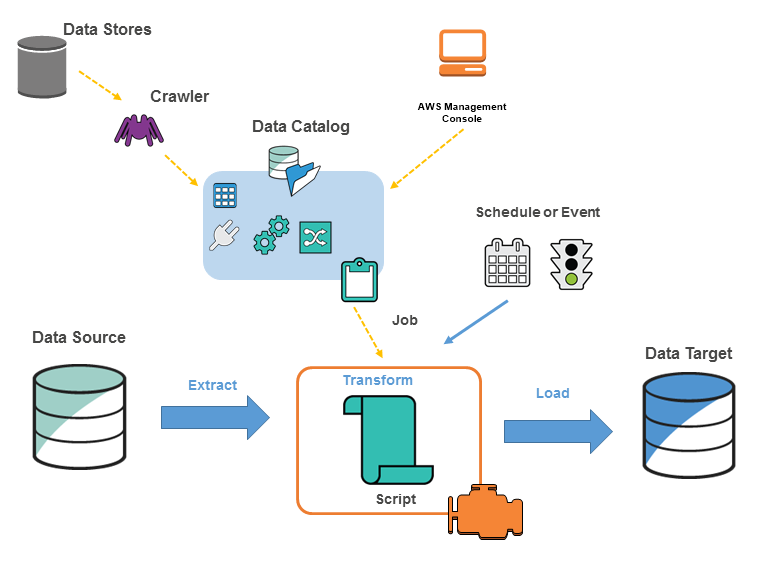
AWS Glue Concepts AWS Glue

Configure crossRegion table access with the AWS Glue Catalog and AWS

AWS Glue Tutorials Dojo

What is Amazon AWS Glue?
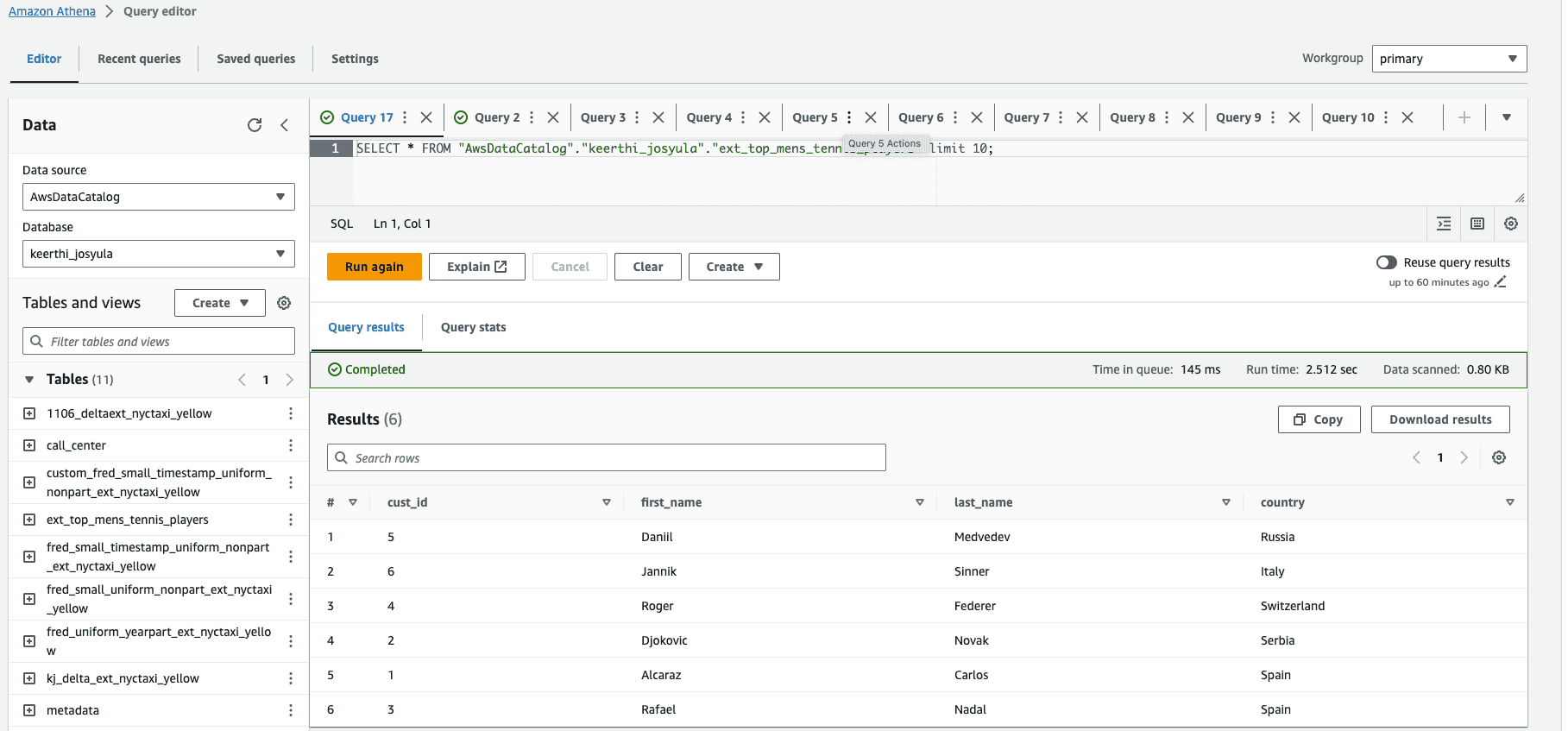
Extract metadata from AWS Glue Data Catalog with Amazon Athena
Using Delta Lake with AWS Glue Delta Lake

Configure crossRegion table access with the AWS Glue Catalog and AWS

How to create table in AWS Glue Catalog using Crawler AWS Glue
Download Jar And Upload To The S3 Bucket.
It Does Not Store The Actual Data, It Only Keeps Track Of Where The Data Is, What It Looks Like, And How It Is.
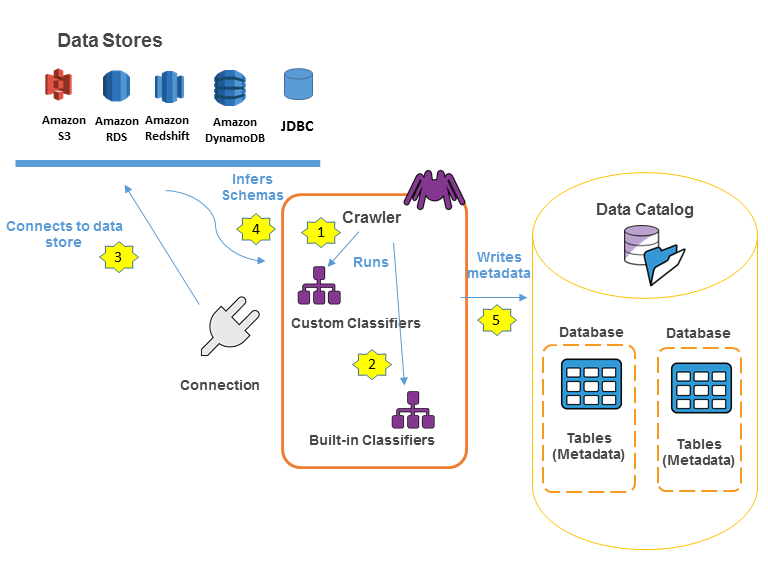
An Aws Glue Crawler Automatically Discovers And Extracts Metadata From A Data Store, And Then It Updates The Aws.
Tell Us More</Main>© 2025 Microsoft Privacy And Cookieslegaladvertiseabout Our Adshelpfeedbackyour Privacy Choicesconsumer Health Privacyallpast 24 Hourspast Weekpast Monthpast Year Refresh
Related Post: